@synchronized
@synchronized 是 iOS 多线程同步锁中性能最差的一个。但是却是所有锁中使用起来最简单的一个。
一般来说,我们就像下面的示例一样来使用:
@synchronized (self) {
}
这样就可以保证 {} 中的代码在多线程的情况下线程安全 ?注意,这里我们有一个? ,如果不合理的使用 @synchronized 同样会导致线程安全问题。
@synchronized 原理
当我们想探究某个方法的底层是怎么实现的,我们可以通过汇编部分来探究这部分代码的具体实现。
我们有两种方法来查看汇编部分
Xcode-->Debug-->Debug Workflow-->Always Show Disassembly显示汇编,然后挂上断点,运行程序Xcode-->Product-->Perform Action-->Assemble **.m文件
当我们在测试项目中,键入如下代码:
- (void)viewDidLoad {
[super viewDidLoad];
@synchronized (self) {
NSLog(@"iOS 成长指北");
}
}
这里,我们使用第二种方法来查看汇编部分,使用第二种方式有便于我们查找代码的具体位置。当我们搜索 :行数 时,找到具体代码的汇编写法,如同红框中的示例。
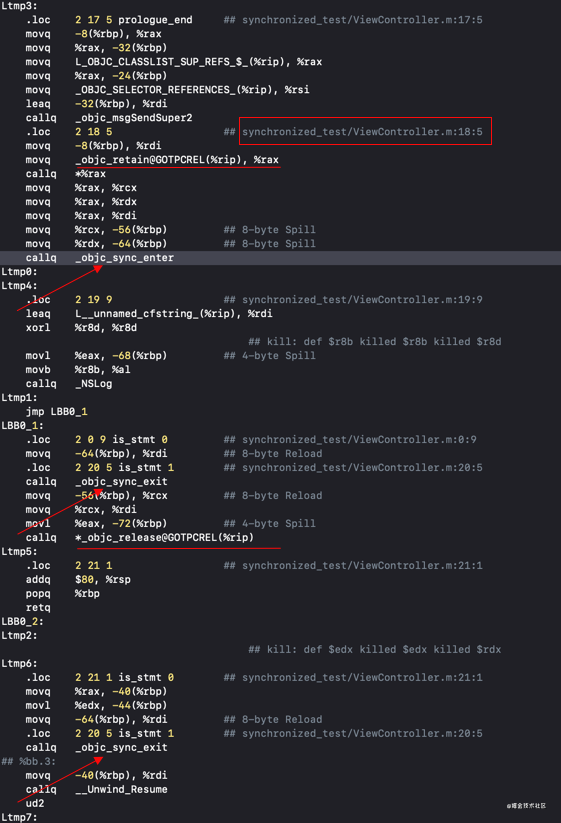
当我们在调用 NSLog 方法时,存在一个_objc_sync_enter 和两个_objc_sync_exit。由此可知,当代码离开 {} 闭包时,会再执行一次 _objc_sync_exit。
萧玉大佬在其《关于 @synchronized,这儿比你想知道的还要多 中说 @synchronized block 会变成 objc_sync_enter 和 objc_sync_exit 的成对调用。从汇编调用上看,似乎并不是?
当执行 release 方法之后,还会调用一次 objc_sync_exit。
源码解析
我们可以查找上述两个方法,最终在 <objc/objc-sync.h> 中找到了_objc_sync_enter 和_objc_sync_exit。让我们来看看其具体实现
typedef struct SyncData {
struct SyncData* nextData;
DisguisedPtr<objc_object> object;
int32_t threadCount;
recursive_mutex_t mutex;
} SyncData;
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, ACQUIRE);
assert(data);
data->mutex.lock();
} else {
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
}
return result;
}
int objc_sync_exit(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, RELEASE);
if (!data) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
} else {
bool okay = data->mutex.tryUnlock();
if (!okay) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
}
}
} else {
}
return result;
}
从源代码和注释中,我们可以发现:
@synchronized创建了一个基于obj为key的递归互斥的锁 recursive_mutex_tmutex- 当
obj为nil时,_objc_sync_enter和_objc_sync_exit并不会执行任何操作 - 我们最终加锁解锁的是
SyncData结构体,是利用id2data(obj, usage)来获取的 SyncData其本质应该是一个链表的头结点,因为使用nextData寻找确定对应值
obj 的作用
为什么我们要在使用 @synchronized 的时候,我们需要传一个obj 呢?我们看一下使用的 obj 的时机
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);
SyncData* result = NULL;
...
}
当我们使用时,通过 StripedMap 来获取对应 obj 的 SyncData 和其被加的自旋锁 spinlock_t。
struct SyncList {
SyncData *data;
spinlock_t lock;
SyncList() : data(nil), lock(fork_unsafe_lock) { }
};
#define LOCK_FOR_OBJ(obj) sDataLists[obj].lock
#define LIST_FOR_OBJ(obj) sDataLists[obj].data
static StripedMap<SyncList> sDataLists;
StripedMap 其本质就是一个哈希表,外层是一个数组,数组里的每个位置存储一个类似链表的结构 SyncList。
使用哈希表的原因就是为了避免多个obj之间的竞争,其哈希函数是基于obj而不是其他。当我们使用 id2data(obj, usage) 函数获取确定的 SyncData 时,首先先根据hash(obj) 获取对应 SyncList 的头节点SyncData,那么后续做什么呢?
我们看看 id2data(obj, usage) 的其他实现
id2data(obj, usage)
如果我们要了解具体如何获取到,我们需要查看
static SyncData* id2data(id object, enum usage why)
{
...
#if SUPPORT_DIRECT_THREAD_KEYS
bool fastCacheOccupied = NO;
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
if (data) {
fastCacheOccupied = YES;
if (data->object == object) {
uintptr_t lockCount;
result = data;
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
switch(why) {
case ACQUIRE: {
lockCount++;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
break;
}
case RELEASE:
lockCount--;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
if (lockCount == 0) {
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
break;
}
return result;
}
}
#endif
SyncCache *cache = fetch_cache(NO);
if (cache) {
unsigned int i;
for (i = 0; i < cache->used; i++) {
SyncCacheItem *item = &cache->list[i];
if (item->data->object != object) continue;
result = item->data;
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) {
case ACQUIRE:
item->lockCount++;
break;
case RELEASE:
item->lockCount--;
if (item->lockCount == 0) {
cache->list[i] = cache->list[--cache->used];
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
break;
}
return result;
}
}
lockp->lock();
{
...
goto done;
}
done:
lockp->unlock();
if (result) {
if (why == RELEASE) {
return nil;
}
#if SUPPORT_DIRECT_THREAD_KEYS
if (!fastCacheOccupied) {
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);
} else
#endif
{
if (!cache) cache = fetch_cache(YES);
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
}
- 当我们拿到
SyncList中SyncData的头结点时,我们需要查找链表中对应的SyncData。 - 当存在缓存时,根据是否支持
SUPPORT_DIRECT_THREAD_KEYS,寻找对应的SyncData的方法实现是不同的。一个是根据tls另一个是使用for循环来查找。 - 当没有没有缓存时,我们需要创建对应的缓存。
- 前面我们说过,
SyncList存在一个自旋锁spinlock_t lock,其加减锁的时机是在加入缓存的时候实现的,线程缓存找不到任何内容时,会加一个自旋锁。但是spinlock_t lock只是一个命名为自旋锁的互斥锁os_unfair_lock罢了。 - 一个值得注意的是,多线程处理时,对应线程可能使用相同的
obj来创建的,但是并没有创建线程缓存,即SyncData存在,但是线程缓存不存在。如果SyncData不存在,我们需要创建一个对应的SyncData。最后创建SyncData的线程缓存,并返回对应的SyncData,并加递归互斥锁。
- 前面我们说过,
1 // obj传入sDataLists
2 #define LIST_FOR_OBJ(obj) sDataLists[obj].data
3
4 // 哈希表结构,内部存SyncList
5 static StripedMap<SyncList> sDataLists;
6
7 // SyncList结构体,内部data就是SyncData
8 struct SyncList {
9 SyncData *data;
10 spinlock_t lock;
11 constexpr SyncList() : data(nil), lock(fork_unsafe_lock) { }
12 };
13
14 // 哈希表结构
15 class StripedMap {
16 enum { StripeCount = 64 };
17
18 struct PaddedT {
19 T value alignas(CacheLineSize);
20 };
21
22 PaddedT array[StripeCount];
23
24 // 哈希函数
25 static unsigned int indexForPointer(const void *p) {
26 uintptr_t addr = reinterpret_cast<uintptr_t>(p);
27 return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
28
29 }
30
31 public:
32 // 此处的p就是上面的obj,也就是obj执行上面的哈希函数对应到数组的index
33 T& operator[] (const void *p) {
34 return array[indexForPointer(p)].value;
35 }
从上述代码看出整体StripedMap是一个哈希表结构,表外层是一个数组,数组里的每个位置存储一个类似链表的结构(SyncList),SyncData 存储的位置具体依赖第25行处的哈希函数,如图:
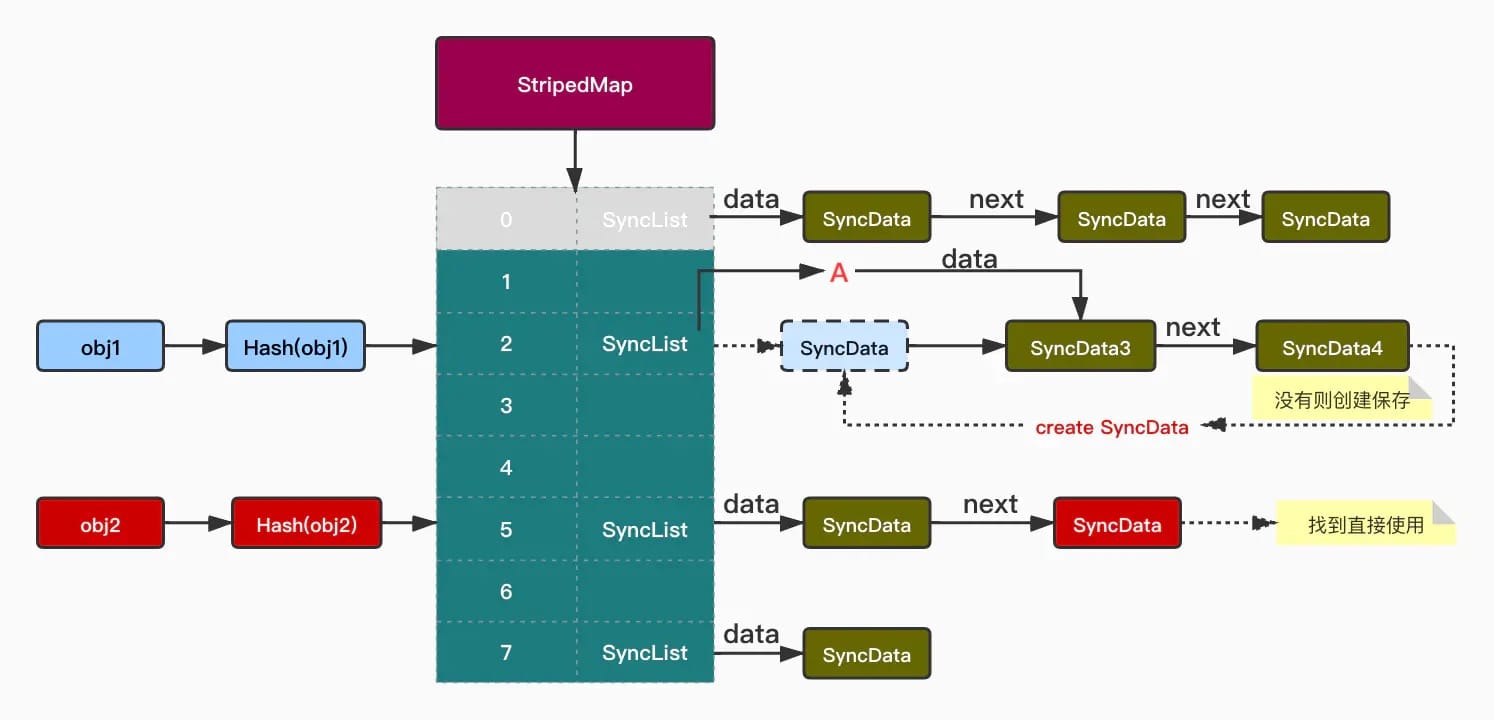
obj1 处,经过哈希函数计算得出索引2,起初我们要顺着上面的 A 线对List进行查找,没找到,将当前的obj插入到最前面,也是为了更快的找到当前使用的对象而这么设计。
// Allocate a new SyncData and add to list.
// XXX allocating memory with a global lock held is bad practice,
// might be worth releasing the lock, allocating, and searching again.
// But since we never free these guys we won't be stuck in allocation very often.
posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData));
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t(fork_unsafe_lock);
result->nextData = *listp;
*listp = result;
慎用 @synchronized(obj)
为什么我们在开头我们说 @synchronized 并不能保证线程安全,当我们使用一个可能变成 nil 的对象作为 obj 时,会发生线程安全问题。
for (NSInteger i = 0; i < 10000; i ++) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
@synchronized (self.array) {
self.array = [NSMutableArray array];
}
});
}
这个例子来自于参考资料 ,稍微修改了一下创建的次数,如果是真机调试可能需要更少的调试次数,模拟器的话其支持的次数会比较多一点。
这个例子会发生崩溃,是因为 ARC 下 setArray: 的方法会执行一个 release 操作,在某个线程中会出现 self.array 为 nil 的情况,而 @synchronized (nil)并不执行加锁解锁操作,会导致线程崩溃。
总结
在所有的线程安全的方案中,@synchronized 以其使用成本成为大部分用户选择,但是性能问题却一直成为他人的诟病。
为什么 @synchronized 是性能最差的呢?因为其包含的操作极为复杂,除了常规的加锁解锁操作以外,还需要考虑哈希表寻址,缓存获取 / 创建缓存等,最差情况下即 N 个 不同的 obj 创建多个不同的 SyncData,并且会调用命名为自旋锁的互斥锁 os_unfair_lock 来实现缓存。